Organize data exploiting relations (that is, sets of tuples)
Among the most used:
- Oracle
- MySQL
- PostgreSQL
- SQLite
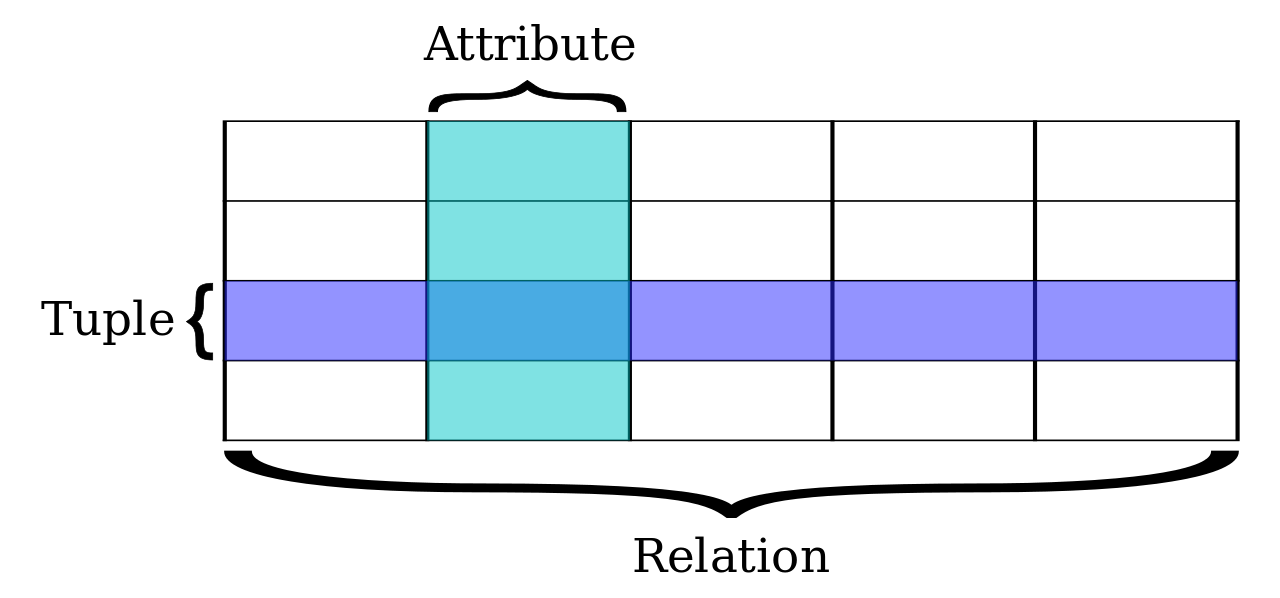
Again, a wide variety:
- MongoDB
- CouchDB
- Cassandra
- Redis
This post is a good starting point in order to understand how they differ.
Because the world is messy!
- Data often happen not to follow a predefined scheme
- specifically, in the data science domain
Incidentally, noSQL gives us interesting advantages:
- dealing with complex structures at once
- scaling horizontally (sharding)
- robustness through redundancy
MongoDB (http://www.mongodb.com) is a document-oriented open source noSQL DBMS.
- Developed since 2007
- In production since the 1.4 release (march 2010)
- Latest stable release: 3.6.5, released on may 2018
- (the name refers to «humongous»)
MongoDB has, however, some critical points:
- indices are organized using B-trees requiring a lot of RAM
- databases tend to take more disk space than their omologous on a RDBMS
- no transactions support is provided
- A db agregates tables
- A table aggregates rows
- A row aggregates values for (fixed) attributes
- Tables can be joined
- A schema fixes how rows in a table are structured
- A db agregates tables collections
- A table collection aggregates rows documents
- A row aggregates values for (fixed) attributes (variable) fields encoded as (name, value) pairs
- Tables cannot be joined (at least, not directly)
- A schema fixes how rows in a table are not structured
- The row of a relational database can be encoded as a sequence of fixed typed values
- This is not possible in MongoDB, according to the lack of a prefixed structure in documents
- This is why documents are described using the JSON format
- JSON (JavaScript Object Notation, http://www.json.org) is a lightweight data-interchange format, easy to read (by humans) and to parse (by computers)
Simply put:
['one', 'two', 'three']
is much more simple than
<array>
<element>one</element>
<element>two</element>
<element>three</element>
</array>

| First Name | Last Name | License plate |
|---|---|---|
| Donald | Duck | 313 |
| Mickey | Mouse | 113 |
| Goofy | 114 |
becomes
{'first-name': 'Donald', 'last-name': 'Duck',
'license-plate': 313},
{'first-name': 'Mickey', 'last-name': 'Mouse',
'license-plate': 113},
{'first-name': 'Goofy', 'license-plate': 114}
MongoDB actually stores data using the BSON format (Binary JSON, http://bsonspec.org/), designed in order to:
- efficiently serialize JSON documents
- easily traverse such documents
- keep lightweightness
Documents can be nested:
{'first-name': 'Donald',
'last-name': 'Duck',
'car': {'model': 'American Bantam',
'license-plate': 313}
}
Arrays are first-class objects in BSON:
{'first-name': 'Donald',
'last-name': 'Duck',
'car': {'model': 'American Bantam',
'license-plate': 313},
'relatives': ['Huey', 'Dewey', 'Louie']
}
| `mongod` | server (listening on port 27017) |
| mongo | javascript client |
| API | for Python, Java, Scala, Ruby, C, C++, ... (http://api.mongodb.org) |
| installation | https://docs.mongodb.com/manual/installation |
$ mongod --dbpath . 2018-05-28T08:47:04.813+0200 I CONTROL [initandlisten] MongoDB starting : pid=5172 port=27017 dbpath=. ... ... $ mongo MongoDB shell version: 3.6.5 ... >
Luckily, you shouldn't need to do that for the interactive part. Ready?
Let's see who's who in Duckburg

import pymongo
client = pymongo.MongoClient('mongodb://localhost:27017/')
duckburg_db = client.duckburg # silently creates db
client.database_names() # it's empty, thus only default dbs will show up
ducks = duckburg_db.ducks # silently creates collection within db
duckburg_db.collection_names() # it will not show up, either
The easiest way to put one document in a db is through the insert_one method
r = ducks.insert_one({'first_name': 'Donald',
'last_name': 'Duck',
'gender': 'M',
'car': {'model': 'American Bantam',
'license_plate': 313},
'birth_year': 1920,
'first_appearance': 1934})
r
The insert_one method returns an object gathering information about the result
acknowledgedis a boolean field which becomesTrueonce the write operation has been acknowledged (there's more here, but we will not consider it)
r.acknowledged
inserted_idis a field containing an univocal identificator for the newly created document (we'll see this more in depth in a moment)
r.inserted_id
print(client.database_names())
print(duckburg_db.collection_names())
- maximum document size: 16MB
- insertion also as an upsert (will see that later)
characters = [
{'first_name': 'Grandma', 'last_name': 'Duck', 'gender': 'F',
'car': {'model': 'Detroit Electric'},
'birth_year': 1833, 'first_appearance': 1943,
'hobbies': ['cooking', 'gardening']},
{'first_name': 'Scrooge', 'last_name': 'McDuck', 'gender': 'M',
'birth_year': 1867, 'first_appearance': 1947,
'hobbies': ['finance', 'savings', 'swimming in money bins']},
{'first_name': 'Gyro', 'last_name': 'Gearloose', 'gender': 'M',
'first_appearance': 1952, 'hobbies': ['invention', 'study']},
{'first_name': 'Ludwig', 'last_name': 'Von Drake', 'gender': 'M',
'first_appearance': 1961, 'hobbies': ['study']}
]
r = ducks.insert_many(characters)
r
r.inserted_ids
duck = ducks.find_one()
duck
There is no guarantee about which document will be retrieved!
Note that JSON-encoded documents can be accessed using the dictionary syntax
duck['first_name']
ducks.find_one()['_id']
The `_id` field is automatically added to all documents; it contains a unique identifier to be used for indexing purposes. By default MongoDB sets it to an `ObjectId` instance
from bson.objectid import ObjectId
[ObjectId(), ObjectId(), ObjectId()]
Selection of several documents matching a query is done through the find method
r = ducks.find()
r
We will speak of cursors in a while, for the moment we just cast them to lists in order to see which documents are matched
list(ducks.find())
Let's build a function providing a more compact visualization of ducks
def show_duck(d):
try:
return '{0} {1}'.format(d['first_name'], d['last_name'])
except KeyError:
return d['first_name']
show_duck(duck)
Based on the existence of specific fields
[show_duck(d) for d in ducks.find({'car': {'$exists': True}})]
Selecting specific values
[show_duck(d) for d in ducks.find({'gender': 'F'})]
[show_duck(d) for d in ducks.find({'first_appearance': 1961})]
On the basis of a relation
[show_duck(d) for d in ducks.find({'first_appearance': {'$gt': 1950}})]
Filtering more than one value for a field
[show_duck(d) for d in ducks.find({'first_appearance': {'$in': [1947, 1961]}})]
Logical conjunction
[show_duck(d) for d in ducks.find({'first_appearance': {'$lt': 1950},
'gender': 'M'})]
Logical disjunction
[show_duck(d) for d in ducks.find({'$or': [{'birth_year': {'$gt': 1900}},
{'gender': 'F'}]})]
Array contents
[show_duck(d) for d in ducks.find({'hobbies': 'study'})]
[show_duck(d) for d in ducks.find({'hobbies': ['study']})]
[show_duck(d) for d in ducks.find({'hobbies.1': 'study'})]
Embedded documents
[show_duck(d) for d in ducks.find({'car.model': 'American Bantam'})]
Regular expressions
import re
regx = re.compile("uck$", re.IGNORECASE)
[show_duck(d) for d in ducks.find({'last_name': regx})]
Using regular expressions, as well as `$lt` or `$gt`, may lead to inefficiency in query execution.
Implemented via a second argument to `find`
- either specifying fields to be shown...
list(ducks.find({'hobbies.1': 'study'},
{'first_name': 1, 'last_name': 1}))
- ...or fields to be excluded.
list(ducks.find({'hobbies.1': 'study'},
{'_id': 0, 'gender': 0, 'birth_year': 0,
'first_appearance': 0, 'hobbies': 0}))
- The select/exclude options are mutually exclusive.
- Only exception: the `_id` field can be filtered out:
list(ducks.find({'hobbies.1': 'study'},
{'first_name': 1, 'last_name': 1, '_id': 0}))
Collections can be indexed specifying a set of fields and the corresponding sort order (the syntax used by is in this case different from the original API)
ducks.create_index([('first_name', pymongo.ASCENDING),
('first_appearance', pymongo.DESCENDING)])
If a query is covered by an index, that is
- all filtered fields,
- and all displayed fields
are within the index, the query is executed via index traversal.
regx = re.compile("^G.*", re.IGNORECASE)
list(ducks.find({'first_name': regx, 'first_appearance': {'$lt': 1955}},
{'_id': 0, 'first_name': 1, 'first_appearance': 1}))
find returns a cursor to the query resultset, accessible via
- invocation of the
nextmethod (untilStopIteration)
cursor = ducks.find()
try:
while True:
print(show_duck(cursor.next()))
except StopIteration:
pass
- positional access through
__getitem__(aka[])
cursor = ducks.find()
show_duck(cursor[1])
show_duck(cursor[4])
(even going back)
show_duck(cursor[2])
listconversion,for-based iteration,
cursor = ducks.find()
for d in cursor:
print(show_duck(d))
- invocation of the
skip,limit,sort, andcountmethods
cursor = ducks.find().sort('last_name', pymongo.DESCENDING)
for d in cursor:
print(show_duck(d))
cursor.rewind()
update method is wicked!ducks.insert_one({'first_name': 'Magica', 'last_name': 'De Spell',
'first_appearance': 1961})
ducks.update({'first_name': 'Magica'}, {'first_appearance': 2000})
Note a couple of things:
- the used method is deprecated;
- it returns a dictionary (instead of an object) summarizing the effects of the operation
Let's double-check:
ducks.find_one({'first_name': 'Magica'})
ducks.find_one({'first_appearance': 2000})
This (deprecated) form of update completely replaced the document!
Use the update_one and update_many methods
# OK, let's revert things
ducks.find_one_and_delete({'first_appearance': 2000})
ducks.insert_one({'first_name': 'Magica', 'last_name': 'De Spell',
'first_appearance': 1961})
ducks.update_one({'first_name': 'Magica'}, {'first_appearance': 2000})
- This error is due to the fact that these methods don't allow to implicitly replace a whole document
- Instead, the use of
$set, which actually updates one or more fields leaving the rest of the document untouched, is enforced
r = ducks.update_one({'first_name': 'Magica'}, {'$set': {'first_appearance': 2000}})
r
The operation returns an object gathering information about the result:
# n. of matched documents
print(r.matched_count)
# n. of modified documents
r.modified_count
# None if no upsertion, id of created document otherwise
# this deals with upsertions, will be explained later on
r.upserted_id
# results in the update-style
r.raw_result
We can check that the method behaves as expected
ducks.find_one({'first_name': 'Magica'})
`update_one` only updates one of the identified documents, `update_many` updates all of them.
There is also the possibility of removing fields in a document, using the `$unset` operator.
ducks.update_one({'first_name': 'Magica'}, {'$unset': {'first_appearance': ''}})
ducks.find_one({'first_name': 'Magica'})
- `$inc` and `$dec` respectively increment and decrement a numeric quantity
- `$push` adds elements to arrays
ducks.update_one({'first_name': 'Gyro'}, {'$push': {'hobbies': 'lamps'}})
ducks.find_one({'first_name': 'Gyro'})
- `$pop` extracts the last or first element in an array
- `$pull` removes all instances of an element from an array
When dealing with arrays, `$` is a special operator denoting the index of the first occurrence of a value matched in an update query
ducks.update_one({'hobbies': 'lamps'}, {'$set': {'hobbies.$': 'robotic lamps'}})
ducks.find_one({'first_name': 'Gyro'})['hobbies']
Note that `$` can be used also in order to dig down to hierarchies. Suppose a document contains the following value for `hobbies`:
[{'name': 'invention', 'day': 'Monday'},
{'name': 'study', 'day': 'Friday'}]The update query modifies the day for the study hobby:
{{'hobbies.name': 'study'}, {'$set': {'hobbies.$.day': 'Tuesday'}}}
What happens if one attempts to update a non-existing document?
- nothing...
- ...unless the `upsert=True` additional argument has been specified in `update_one` or `update_many`: in this case the operation results in an insert-upon-update (upsert).
- at most one document identified by a query
ducks.delete_one({'first_name': 'Ludwig'})
- all documents identified by a query
ducks.delete_many({'first_name': 'Ludwig'})
- all documents in a collection
ducks.delete_many()
- a collection
ducks.drop()
- a database
client.drop_database('duckburg')
# or
duckburg_db.command('dropDatabase')
- Scalability in MongoDB is achieved through sharding, that is distributing and replicating data across several machines
- This however doesn't allow to perform joins automatically
`ObjectId`s can be used to manually recreate one-to-many joins...
donald_id = ducks.find_one({'first_name': 'Donald'})['_id']
for d in ['Huey', 'Dewey', 'Louie']:
ducks.insert_one({'first_name': d, 'uncle': donald_id})
...at the price of an additional query (to recover, in this case, the uncle).
Many-to-many joins can be implemented
- using arrays
ducks.insert_one({'first_name': 'Donald', 'last_name': 'Duck',
'relatives': [ObjectId('516405b8b356cd6125b74e89'),
ObjectId('516405b8b356cd6125b74e8a'),
ObjectId('516405b8b356cd6125b74e8b')]})
ducks.find({'relatives': ObjectId('516405b8b356cd6125b74e8a')})
- or embedded documents
ducks.insert_one({'first_name': 'Donald', 'last_name': 'Duck',
'relatives': [{'first_name': 'Huey'},
{'first_name': 'Dewey'},
{'first_name': 'Louie'}]})
ducks.find_one({'relatives.first_name': 'Dewey'})
- a possible solution (duplication not to be necessarily demonized)
- critical limit: the maximal size of each document is 16 MBytes
- (aside note: the whole text of Shakespeare's Hamlet requires 200 Kbytes)
- the actual price to be paid for this is in having a higher number of queries (for instance, when duplicate data are updated)
There's no universal solution: the choice depends on the problem under study, as well as on personal design style
- Sharding
- Map-Reduce
- Aggregation framework
- ...
- Download the notebook and dataset in a computer having mongodb and jupyter installed
- Unzip the dataset and open the notebook
- Solve the proposed challenges adding cells just below each question
- Save your results in a notebook named using your name followed by "-mongodb"
The following cells contain some challenges: solve them and send the results to malchiodi@di.unimi.it, specifying Sophia Antipolis lecture assignment 1 as subject.
You can consult with classmates but what you send should be the exclusive result of your work, and in any case do not copy code.
Import the dataset¶
We will work with a book catalog already encoded in JSON format and available at the URL https://github.com/ozlerhakan/mongodb-json-files/blob/master/datasets/catalog.books.json
You don't need to download this dataset, as it is already in the Docker image we are using. You need however to import it into MongoDB: the next cell takes care of this task, creating a books collection within a db having the same name.
%%bash
mongoimport --db books --collection books --file catalog.books.json
Inspect data¶
Although we saw that a tabular description might not be the best resource to be used when visualizing noSQL data, we can build and show a Pandas dataframe as a quick way to peek into the dataset.
db = client.books
books = db.books
import pandas as pd
pd.DataFrame(list(books.find().limit(5)))
- How many books are there?
- Which is the highest number of co-authors in a book?
- How many distinct authors are there?
- Which author has the highest number of coauthors?
- How many coauthors has this author and who are these coauthors?
- Deduplicate author
- Remove grouped authors
- Write (but don't execute!) a query removing books with null authors
- Which class is used in order to store time stamps?
- How many books were published in 2009?
- Which are the least and the most recent publication years?
- Display a bar plot showing the number of all published books between 1992 and 2015
- Build a function
get_coauthors_for_yearstaking two years as arguments and returning a dictionary associating each author to the set of his coauthors within the corresponding time span (if any of the arguments isNonethe search should be done on all books) - Use the function
get_coauthors_for_yearsin order to draw the collaboration graph of all books published between 1997 and 1999 (Hint: use thenextworkx.Graphclass, specifically itsadd_nodeandadd_edgemethods, as well as thenetworkx.drawmethod in order to show a graph) - Build and save the collaboration matrix of all authors
- Build and save the collaboration matrix of all books
- Build and save additional information
How many books are there?¶
Which is the highest number of co-authors in a book?¶
How many distinct authors are there?¶
Which author has the highest number of co-authors?¶
Note: empty string do not count as authors
How many coauthors has this author?¶
Who are these coauthors?¶
Deduplicate author¶
It seems our data are not that clean: one author is actually the empty string, Kimberly Tripp occurs twice (one time with the middle name, another one without it), and in two cases the author's name is actually the name for a group of authors. Let's clean up these things. First of all we can deduplicate records referring to Kimberly Tripp: write an update query modifying all occurrences of 'Kimberly L. Tripp' into 'Kimberly Tripp'
Remove grouped authors¶
Write an update query removing all occurrences of 'Contributions from 53 SQL Server MVPs' and Contributions from 53 SQL Server MVPs; Edited by Paul Nielsen as author names, replacing them with the empty string.
Write (but don't execute!) a query removing books with missing author¶
Write a query which would remove all documents having the empty string as author. Don't execute the query, as it will remove interesting information we will need later on.
Which class is used in order to store time stamps?¶
How many books were published in 2009?¶
Which are the least and the most recent publication years?¶
Display a bar plot showing the number of all published books between 1992 and 2015¶
Build a function get_coauthors_for_years taking two years as arguments and returning a dictionary associating each author to the set of his coauthors within the corresponding time span (if any of the arguments is None the search should be done on all books)¶
Use the function get_coauthors_for_years in order to draw the collaboration graph of all books published between 1997 and 1999¶
The collaboration graph here is intended as a graph having authors as nodes and connecting two nodes if the corresponding authors have coauthored at least one book.
Hint: use the nextworkx.Graph class, specifically its add_node and add_edge methods, as well as the networkx.draw method in order to show a graph.
Build and save the collaboration matrix of all authors¶
Consider all books regardless of publication year, and build the authors' collaboration matrix, that is a square matrix whose dimension equals the number of authors. Entry $(r, c)$ in this matrix (where $r$ and $c$ refer respectively to rows and columns) should be 0 if $r$-th and $c$-th author never coauthored a book, otherwise it should be set to $\frac{1}{n_c}$, where $n_c$ is the total number of coauthors of $c$-th author.
We'll be interested actually only in non-null entries: save them as one row of a CSV file using the format $(r, c, m_{rc})$, being $m_{rc}$ the non-null element in row $r$ and column $c$. Use the name author-connections.csv for this file.
Hint: if you get confused about what to place in rows and columns, take in mind that the resulting matrix should be columns-wise stochastic, that is the sum of all elements in any columns has to be equal to 1.
Build and save the collaboration matrix of all books¶
The collaboration matrix of books is obtained in the same way as those of authors, where now two books are connected (and thus identify a non-null entry in the matrix) if they share at least one author. Also in this case, the obtained matrix should be column-wise stochastic.
Build and save additional information¶
Write in a CSV file the association of each book to the corresponding indices of rows and columns in the previously produced book connection matrix: each row of the file will have the format $(i,t)$, where $i$ is the index and $t$ is the title. Name this file 'book-index.csv'
Write a file 'book-categories.csv' in which each line has the format $(i, j)$, where $i$ is an index of the book (in the previously produced matrix and vector) and $j$ is 1 if the corresponding book has the Java category in the dataset, and 0 otherwise.